A simple function that subsamples a data frame or numeric vector in order to "thin" large datasets.
Arguments
- x
data frame or vector. The data to subsample.
- n
numeric. Subsample every
nelements or rows.- length.out
numeric. Subsample to a specific length or number of rows.
- random_start
logical. Defaults to FALSE. If TRUE, randomises the start position from which to start the subsample (applies to
ninput only).- plot
logical. Defaults to TRUE. Plots the data. If there are multiple columns in the data frame, only the first two are plotted. Vectors are plotted against a position index.
Details
Two subsampling methods are provided. The n input selects every n'th
element or row, or alternatively the length.out input uniformly subsamples
the data to the desired length.
More
For additional help, documentation, vignettes, and more visit the respR
website at https://januarharianto.github.io/respR/
Examples
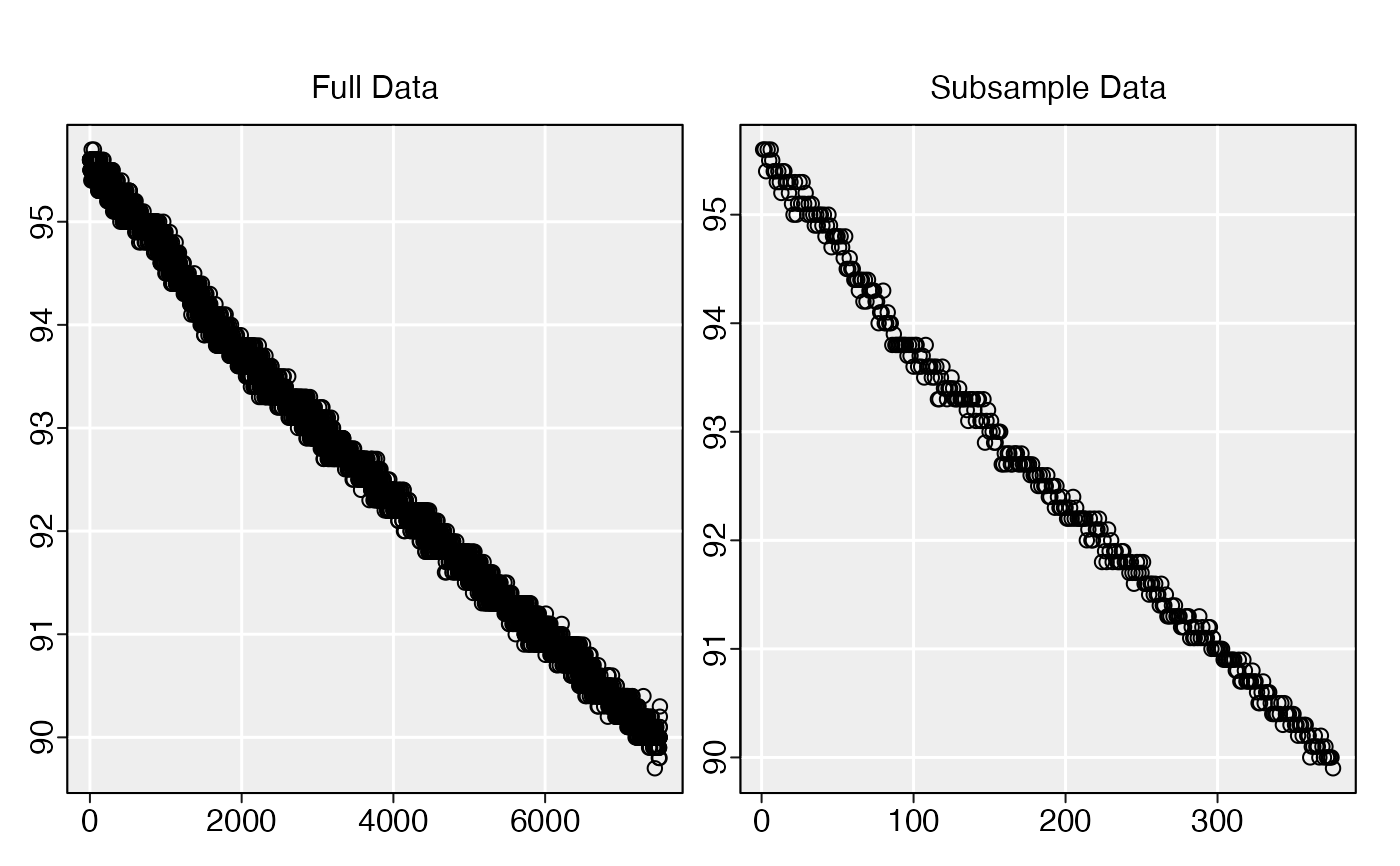
# Subsample by every 200th row:
subsample(squid.rd, n = 200)
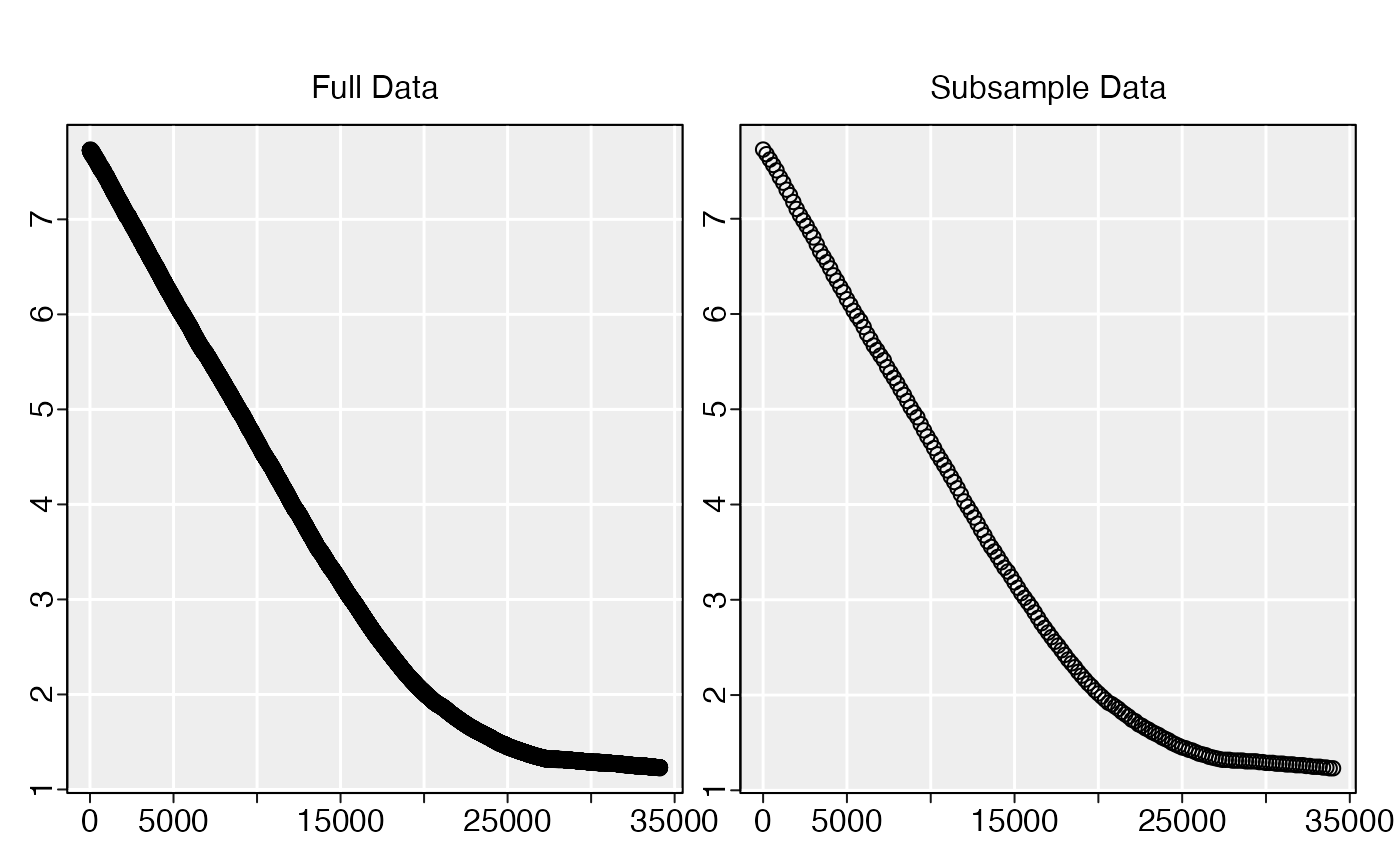 # Subsample to 100 rows:
subsample(sardine.rd, length.out = 100)
#> subsample: plotting first column of data only.
# Subsample to 100 rows:
subsample(sardine.rd, length.out = 100)
#> subsample: plotting first column of data only.
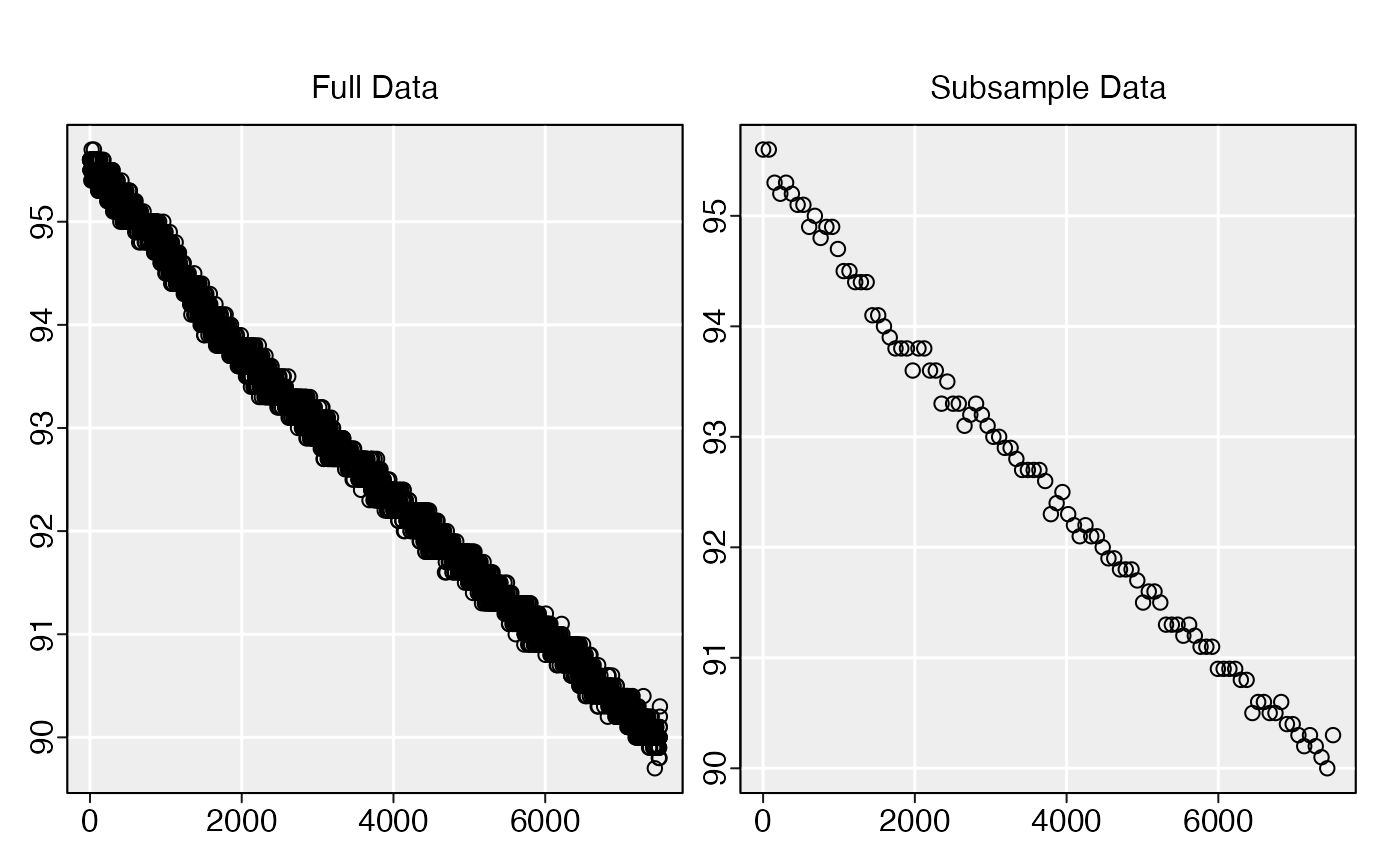 # Subsample with random starting position:
subsample(sardine.rd, n = 20, random_start = TRUE)
#> subsample: plotting first column of data only.
# Subsample with random starting position:
subsample(sardine.rd, n = 20, random_start = TRUE)
#> subsample: plotting first column of data only.
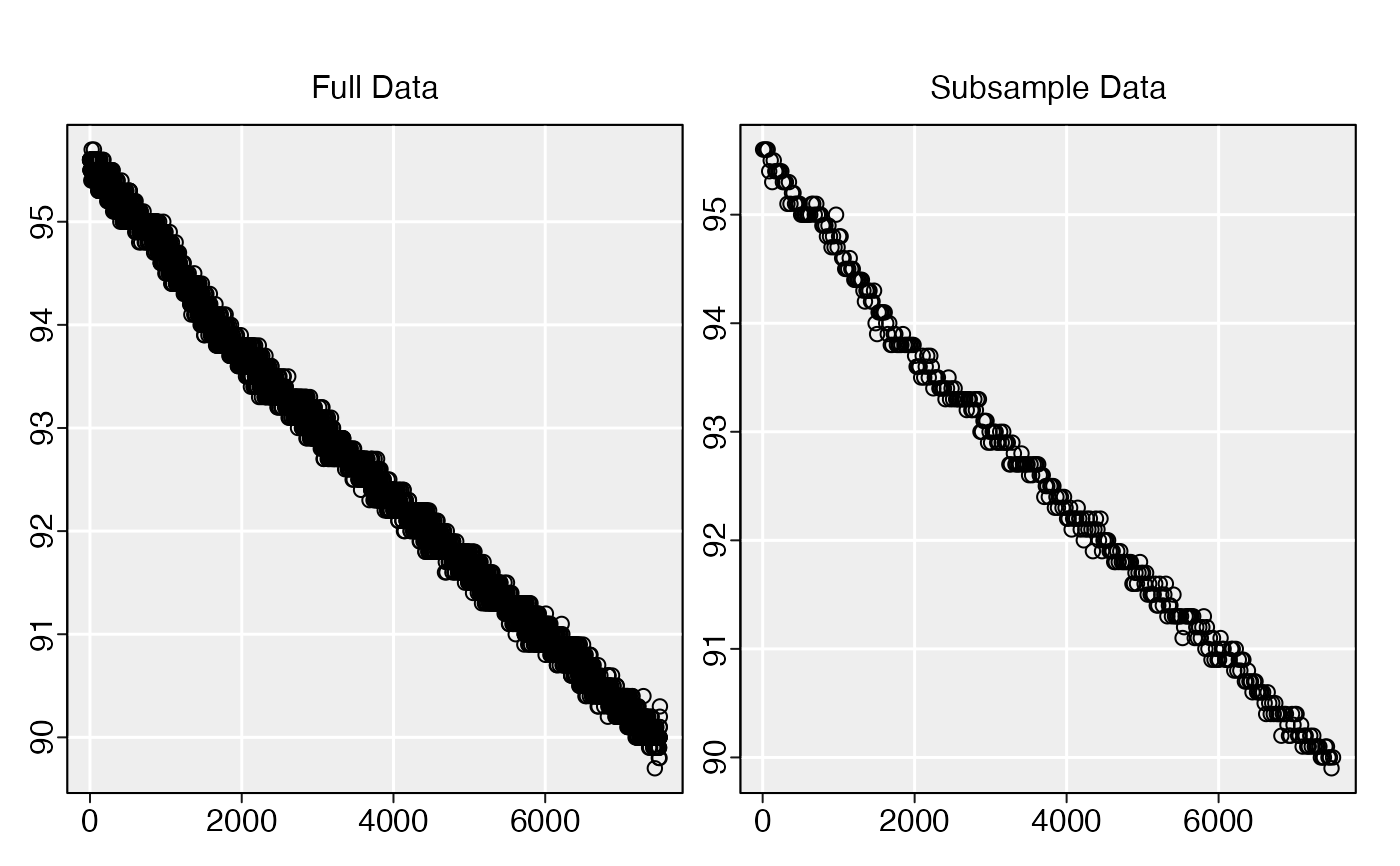 # Subsample a vector
subsample(sardine.rd[[2]], n = 20)
# Subsample a vector
subsample(sardine.rd[[2]], n = 20)